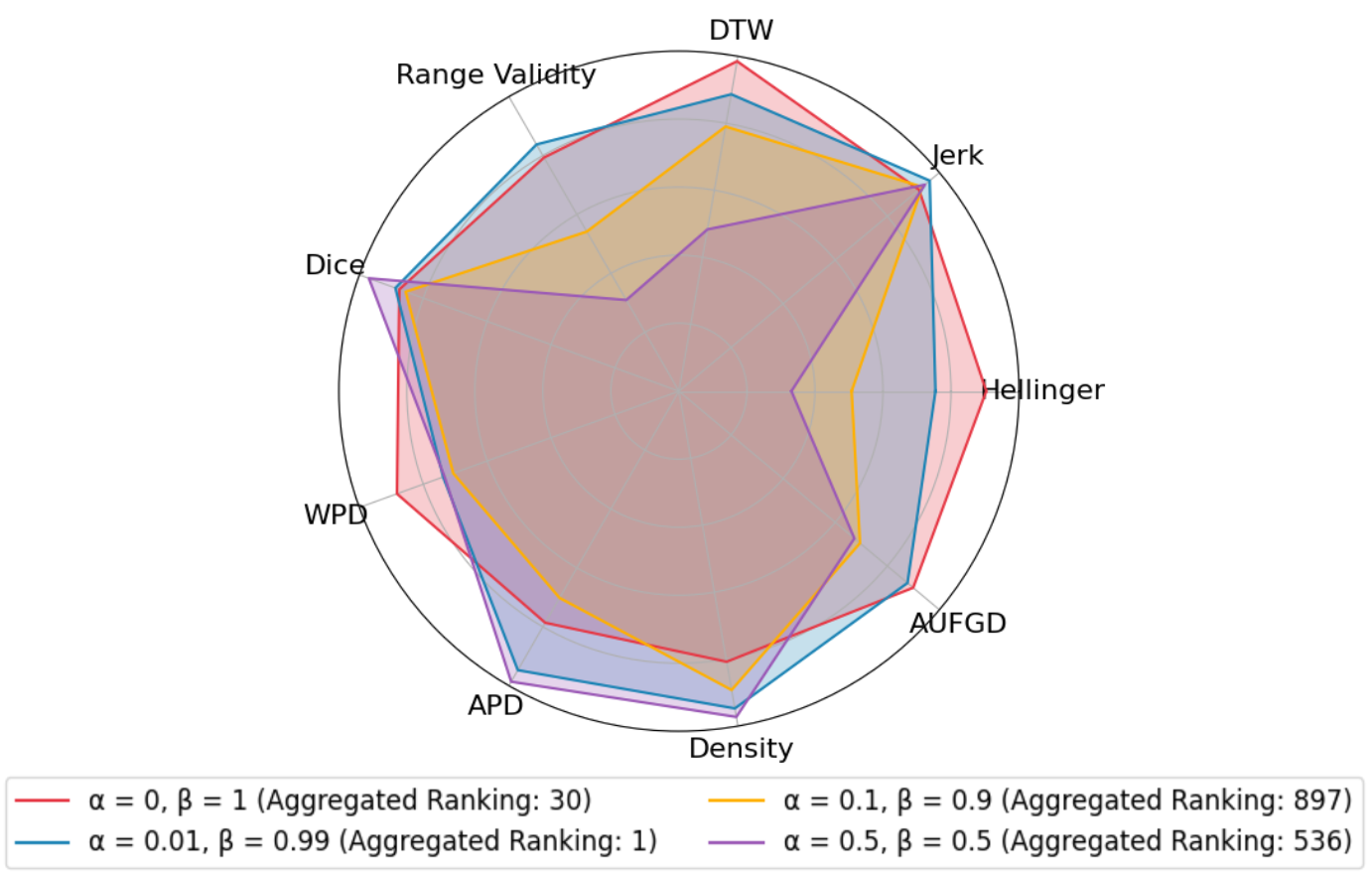
Evaluating the quality of generated nonverbal behavior remains a major challenge in the development of generative
models. While human evaluations are reliable, they are costly and impractical for large-scale or iterative
optimization. In this work, we propose an objective evaluation framework based on aggregated ranks across multiple
fidelity and diversity metrics, computed from both raw features and learned latent representations. Compared to
existing works, our framework emphasizes consistency across multiple metrics, aiming to provide a more holistic
assessment.